دورههای پیشنهادی


 با کراس در پایتون و R")

")









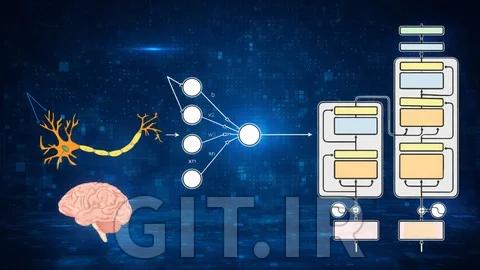







شبکه عصبی مصنوعی (Artificial neural network) چیست؟
شبکه های عصبی مصنوعی (ANN) یا سیستم های اتصال دهنده، سیستم های محاسباتی هستند که به صورت مبهم از شبکه های عصبی بیولوژیکی مغز حیوانات الهام گرفته می شوند. چنین سیستم هایی "یاد می گیرند" که وظایف خود را با در نظر گرفتن مثال ها انجام دهند، عموماً بدون اینکه با قوانین خاص وظیفه برنامه ریزی شوند. به عنوان مثال، در تشخیص تصویر، آنها ممکن است یاد بگیرند با تجزیه و تحلیل تصاویر مثال هایی که به صورت دستی به عنوان "گربه" یا "بدون گربه" و با استفاده از نتایج برای شناسایی گربه ها در تصاویر دیگر، تصاویر حاوی گربه ها را شناسایی کنند. آنها این کار را بدون هیچ گونه آگاهی قبلی از گربه ها انجام می دهند، به عنوان مثال، آنها دارای خز، دم، خط و صورت مانند گربه هستند. در عوض، آنها به طور خودکار ویژگی های شناسایی را از نمونه های پردازش شده، تولید می کنند.
ANN مبتنی بر مجموعه ای از واحدها یا گره های متصل به نام نورون های مصنوعی است که نورون ها را در مغز بیولوژیکی به راحتی مدل می کنند. هر اتصال، مانند سیناپس های موجود در مغز بیولوژیکی، می تواند سیگنالی را به سلول های عصبی دیگر منتقل کند. نورون مصنوعی، سیگنالی دریافت می کند سپس آن را پردازش می کند و می تواند نورون های متصل به آن را سیگنال کند.
در پیاده سازی های ANN، "سیگنال" در اتصال یک عدد واقعی است و خروجی هر نورون توسط برخی عملکردهای غیرخطی از مجموع ورودی های آن محاسبه می شود. اتصالات، لبه نامیده می شوند. نورون ها و لبه ها معمولاً وزنی دارند که با پیشرفت یادگیری تنظیم می شود. وزن باعث افزایش یا کاهش استحکام سیگنال در اتصال می شود. نورون ها ممکن است آستانه ای داشته باشند که فقط در صورت عبور سیگنال جمع شده از آن آستانه، سیگنال ارسال شود. به طور معمول، نورون ها در لایه ها جمع می شوند. لایه های مختلف ممکن است تحولات متفاوتی را بر روی ورودی های خود انجام دهند. سیگنال ها از لایه اول (لایه ورودی) به لایه آخر (لایه خروجی)، احتمالاً بعد از طی کردن لایه ها چندین بار حرکت می کنند.
هدف اصلی رویکرد ANN حل مشکلات به همان روشی است که مغز انسان انجام می دهد. با این حال، با گذشت زمان، توجه به انجام کارهای خاص منتقل شد و منجر به انحراف از زیست شناسی شد. شبکه های عصبی در کارهای مختلفی از جمله بینایی رایانه ای، تشخیص گفتار، ترجمه ماشینی، فیلتر شبکه های اجتماعی، گیم پد ها و بازی های ویدیویی، تشخیص پزشکی و حتی در فعالیت هایی که به طور سنتی برای انسان ها مانند نقاشی در نظر گرفته شده اند مورد استفاده قرار گرفته است.
تاریخچه شبکه عصبی مصنوعی
وارن مک کالوچ و والتر پیتز (1943) با ایجاد مدل محاسباتی برای شبکه های عصبی موضوع را باز کردند. در اواخر دهه 1940، D. O. Hebb فرضیه یادگیری را بر اساس مکانیسم پلاستیک عصبی ایجاد کرد که به عنوان یادگیری هبیان معروف شد. فارلی و وسلی کلارک ابتدا برای شبیه سازی شبکه هبیان از ماشین های محاسباتی، سپس به عنوان "حسابگرها" استفاده کردند. روزنبلات (1958) این پرسپترون را ایجاد کرد. اولین شبکه های کاربردی با لایه های بسیاری توسط Ivakhnenko و Lapa در سال 1965 به عنوان گروه روش پردازش داده ها منتشر شد. اصول اولیه بکارگیری مداوم در زمینه نظریه کنترل توسط کلی در سال 1960 و برایسون در سال 1961 با استفاده از اصول برنامه نویسی پویا بدست آمده است.
در سال 1970، Seppo Linnainmaa روش کلی برای تمایز خودکار (AD) شبکه های متصل گسسته از توابع متفاوت متمایز را منتشر کرد. در سال 1973، Dreyfus از backpropagation برای تطبیق پارامترهای کنترل کننده به نسبت شیب خطا استفاده کرد. الگوریتم backpropagation Werbos (1975) آموزش عملی شبکه های چند لایه را امکان پذیر کرد. در سال 1982، او روش AD Linnainmaa را به روش مورد استفاده گسترده در شبکه های عصبی بکار برد. پس از آن تحقیقات به دنبال مینسکی و پاپرت (1969) که کشف کردند که گیرنده های اصلی قادر به پردازش مدار منحصر به فرد یا مدار نیستند و کامپیوترها فاقد قدرت کافی برای پردازش شبکه های عصبی مفید هستند. در سال 1992، حداکثر جمع آوری برای کمک به کمترین تغییر ناپذیری و تحمل تغییر شکل برای کمک به تشخیص شی سه بعدی ارائه شد. اشمیتدور سلسله مراتب چند سطحی از شبکه ها (1992) را با یادگیری بدون نظارت سطح در زمان آموزش داد و با پشتیبان گیری دقیق تنظیم کرد.
جفری هینتون و همکاران، (2006) يك بازنمايي سطح بالا با استفاده از لايه هاي متوالي متغيرهاي نهفته و ارزشي با ارزش واقعي با يك دستگاه بولتزمن محدود براي مدل سازي هر لايه پيشنهاد كردند. در سال 2012، نگ و دین شبکه ای ایجاد کردند که یاد گرفتند مفاهیم سطح بالاتر مانند گربه ها را فقط از تماشای تصاویر بدون برچسب تشخیص دهند. قبل از آموزش بدون نظارت و افزایش توان محاسباتی از طریق GPU و محاسبات توزیع شده، امکان استفاده از شبکه های بزرگتر، به ویژه در مشکلات تصویر و تشخیص بصری، که به عنوان "یادگیری عمیق" شناخته شده اند، فراهم شده است.
Ciresan و همکارانش (2010) نشان دادند که با وجود مشکل گرادیان ناپدید شده، GPU پردازش پشتیبان را برای شبکه های عصبی تغذیه ای چند لایه امکان پذیر می کند. به عنوان مثال، حافظه کوتاه مدت دو جهته و چند بعدی (LSTM) Graves و همکاران، در سال 2009 بدون هیچگونه آگاهی قبلی درباره این سه زبان که باید یاد بگیرند، سه رقابت در زمینه شناسایی خط نوشتاری متصل به دست آورد. Ciresan و همکارانش اولین شناسه های الگوی را برای دستیابی به عملکردهای انسانی - رقابتی - فوق بشری بر روی معیارهایی مانند شناخت علائم راهنمایی و رانندگی ساختند.
انواع شبکه عصبی مصنوعی

شبکه های عصبی محلی در خانواده گسترده ای از تکنیک ها پیشرفت کرده اند که پیشرفت های هنری را در حوزه های مختلف پیش برده اند. ساده ترین نوع ها دارای یک یا چند مؤلفه ایستا، از جمله تعداد واحد، تعداد لایه ها، وزن واحد و توپولوژی هستند. نوع پویا اجازه می دهد تا یک یا چند مورد از طریق یادگیری تکامل یابند. حالت دوم بسیار پیچیده تر است اما می تواند دوره های یادگیری را کوتاه کند و نتایج بهتری را بدست آورد. برخی از انواع این امکان را دارد که یاد می گیرد که توسط "اپراتور" تحت نظارت قرار بگیرند، در حالی که برخی دیگر مستقل کار می کنند. برخی از انواع کاملاً سخت افزاری کار می کنند، برخی دیگر کاملاً نرم افزاری هستند و در رایانه های عمومی کاربرد دارند.
برخی از پیشرفت های اصلی عبارتند از: شبکه های عصبی کانونی که در پردازش داده های بصری و سایر داده های دو بعدی به خصوص موفق هستند. حافظه کوتاه مدت طولانی از بروز مشکل گرادیان ناپدید می شود و می تواند سیگنال هایی را در خود بگیرد که ترکیبی از اجزای کم فرکانس پایین و کمکی را برای تشخیص گفتار بزرگ، ترکیب متن به گفتار و سر صحبت واقعی عکس ها دارند. شبکه های رقابتی مانند شبکه های مخالف مولد که در آن چندین شبکه (با ساختار متفاوت)، بر روی کارهایی مانند برنده شدن در بازی یا فریب حریف در مورد صحت ورودی، با یکدیگر به رقابت می پردازند.
هفت نوع از شبکه های عصبی مصنوعی:
- Multilayer perceptron (MLP)
- Convolutional neural network (CNN)
- Recursive neural network (RNN)
- Recurrent neural network (RNN)
- Long short-term memory (LSTM)
- Sequence-to-sequence models
- Shallow neural networks
کاربرد شبکه عصبی مصنوعی
استفاده از شبکه های عصبی مصنوعی نیاز به درک ویژگی های آنها دارد.
- انتخاب مدل: این بستگی به نمایش داده ها و کاربرد دارد. مدل های بسیار پیچیده، یادگیری را کند می کنند.
- الگوریتم یادگیری: تجارت بین تعداد زیادی از الگوریتم های یادگیری وجود دارد. تقریباً هر الگوریتم به خوبی با پارامترهای مناسب برای آموزش مجموعه داده خاص کار خواهد کرد. با این حال، انتخاب و تنظیم الگوریتم برای آموزش داده های غیبی نیاز به آزمایش قابل توجهی دارد.
- استحکام: اگر مدل، عملکرد هزینه و الگوریتم یادگیری مناسب انتخاب شوند، ANN حاصل می تواند قوی شود.
قابلیت های ANN در دسته های گسترده زیر قرار می گیرند:
- تقریب عملکرد، یا تحلیل رگرسیون، از جمله پیش بینی سری زمانی، تقریب تناسب اندام و مدل سازی.
- طبقه بندی، از جمله تشخیص الگوی و دنباله، تشخیص تازگی و تصمیم گیری متوالی.
- پردازش داده ها از جمله فیلتر، خوشه بندی، جداسازی هسته منبع و فشرده سازی.
- رباتیک، از جمله کارگردانی manipulators و پروتزها.
- کنترل، از جمله کنترل عددی رایانه.
برنامه های کاربردی
شبکه های عصبی مصنوعی به دلیل توانایی تولید مثل و مدل سازی فرآیندهای غیرخطی، در بسیاری از رشته ها کاربردهایی پیدا کرده اند. مناطق برنامه شامل شناسایی سیستم و کنترل سیستم (کنترل وسیله نقلیه، پیش بینی مسیر، کنترل فرآیند، مدیریت منابع طبیعی)، شیمی کوانتومی، بازی های عمومی، تشخیص الگو (سیستم های راداری، شناسایی چهره، طبقه بندی سیگنال، بازسازی سه بعدی، تشخیص اشیاء و موارد دیگر)، تشخیص توالی (ژست، گفتار، تشخیص متن دست نویس و چاپی)، تشخیص پزشکی، امور مالی (به عنوان مثال سیستم های تجاری خودکار)، داده کاوی، ویژوال سازی، ترجمه ماشینی، فیلتر شبکه های اجتماعی و فیلتر اسپم پست الکترونیکی. از ANN برای تشخیص سرطان ها از جمله سرطان ریه، سرطان پروستات، سرطان کولورکتال و تمایز خطوط سلولی سرطانی بسیار تهاجمی از خطوط کمتر تهاجمی استفاده می شود و فقط با استفاده از اطلاعات مربوط به شکل سلول ها استفاده می شود.
شبکه های عصبی محلی برای سرعت بخشیدن به تجزیه و تحلیل قابلیت اطمینان و پیش بینی زیرساخت های در معرض حوادث طبیعی شهرک های بنیادی استفاده شده اند. ANN ها همچنین برای ساخت مدل های جعبه سیاه در علوم زمین مورد استفاده قرار می گیرند: هیدرولوژی، مدل سازی اقیانوس، مهندسی ساحلی و ژئومورفولوژی. شبکه های عصبی محلی در امنیت سایبری به کار گرفته شده اند و هدف آنها تمایز بین فعالیت های مشروع و اقدامات مخرب است. به عنوان مثال، از یادگیری ماشینی برای طبقه بندی بدافزارهای اندرویدی، برای شناسایی دامنه های متعلق به بازیگران تهدید و برای شناسایی URL هایی که خطر امنیتی دارند، استفاده شده است. تحقیقات در مورد سیستم های ANN که برای آزمایش نفوذ طراحی شده اند، برای شناسایی بات نت، کلاهبرداری کارت اعتباری و نفوذ شبکه می باشد.
شبکه های عصبی به عنوان ابزاری برای شبیه سازی خواص سیستم های کوانتومی باز با بدن بسیار زیاد پیشنهاد شده اند. در تحقیقات مغزی، ANN رفتار کوتاه مدت نورون های فردی را مورد مطالعه قرار داده است، پویایی مدار عصبی ناشی از تعامل بین نورون های فردی است و اینکه چگونه می توان رفتار را از ماژول های عصبی انتزاعی که نماینده زیر سیستم کامل هستند، ناشی می کند. مطالعات، انعطاف پذیری طولانی مدت و کوتاه مدت سیستم های عصبی و ارتباط آنها با یادگیری و حافظه از نورون فرد به سطح سیستم را در نظر گرفته اند.
شبکه عصبی مصنوعی در یادگیری ماشین
شبکه های عصبی محلی نه تنها در برنامه های کاربردی یادگیری ماشینی بلکه در موقعیت ها و برنامه های کاربردی که ده ها سال است مورد استفاده قرار می گیرند. ANN با نام MADALINE در واقع اولین کسی بود که در سال 1959 بر روی مشکل در دنیای واقعی اعمال شد. این مدل پژواک های تولید شده توسط خطوط تلفنی را با استفاده از لایه از بین می برد تا به عنوان فیلتر صوتی عمل کند.
یکی از کاربردهای جدید ANN در فناوری های تشخیص صدا است. برای این برنامه، ANN باید آموزش داده شود تا بطور دقیق آنچه مردم با صدای و لهجه های مختلف می گویند را بفهمید. این داده ها با نگاه کردن به ریاضیات پشت امواج صوتی و آنچه که کلمه خاص را تشکیل می دهد، آموزش می گیرند. پس از آموزش این داده ها، می توانید داده ها را وارد مدل کرده و به لایه های مخفی اجازه دهید محاسبه کنند. این لایه ها یاد می گیرند که از الگوی موج هایی که از زبان تقلید می کنند اولویت بندی کنند. هنگامی که این لایه های پنهان اطلاعات دقیق را به دست می آورند، این مدل آماده است تا برای تشخیص فرامین صوتی مختلفی که انسان به آن می دهد، مورد استفاده قرار گیرد.
مثال شبکه عصبی مصنوعی
شبکه های عصبی هسته اصلی یادگیری عمیق است، زمینه ای که در بسیاری از مناطق مختلف کاربردهای عملی دارد. امروزه شبکه های عصبی برای طبقه بندی تصویر، تشخیص گفتار، تشخیص اشیا و غیره مورد استفاده قرار می گیرند. اکنون، سعی می کنیم واحد اساسی پشت این حالت تکنیکی را درک کنیم. نورون واحد ورودی داده شده را به مقداری خروجی تبدیل می کند. بسته به ورودی داده شده و وزن های اختصاص داده شده به هر ورودی، تصمیم بگیرید نورون شلیک شود یا خیر. فرض کنیم نورون دارای 3 اتصال ورودی و خروجی است.

در مثال داده شده از تابع فعال سازی tanh در پایتون استفاده خواهیم کرد. هدف نهایی یافتن مجموعه بهینه وزن برای این نورون است که نتایج صحیحی را ایجاد می کند. این کار را با آموزش نورون با چند مثال مختلف آموزشی انجام دهید. در هر مرحله خطای مربوط به خروجی نورون را محاسبه کرده و شیب ها را به عقب بکشید. مرحله محاسبه خروجی نورون، forward propagation نامیده می شود در حالی که محاسبه شیب ها back propagation نامیده می شود.
در زیر اجرای آن آورده شده است:
# Python program to implement a
# single neuron neural network
# import all necessery libraries
from numpy import exp, array, random, dot, tanh
# Class to create a neural
# network with single neuron
class NeuralNetwork():
def __init__(self):
# Using seed to make sure it'll
# generate same weights in every run
random.seed(1)
# 3x1 Weight matrix
self.weight_matrix = 2 * random.random((3, 1)) - 1
# tanh as activation fucntion
def tanh(self, x):
return tanh(x)
# derivative of tanh function.
# Needed to calculate the gradients.
def tanh_derivative(self, x):
return 1.0 - tanh(x) ** 2
# forward propagation
def forward_propagation(self, inputs):
return self.tanh(dot(inputs, self.weight_matrix))
# training the neural network.
def train(self, train_inputs, train_outputs,
num_train_iterations):
# Number of iterations we want to
# perform for this set of input.
for iteration in range(num_train_iterations):
output = self.forward_propagation(train_inputs)
# Calculate the error in the output.
error = train_outputs - output
# multiply the error by input and then
# by gradient of tanh funtion to calculate
# the adjustment needs to be made in weights
adjustment = dot(train_inputs.T, error *
self.tanh_derivative(output))
# Adjust the weight matrix
self.weight_matrix += adjustment
# Driver Code
if __name__ == "__main__":
neural_network = NeuralNetwork()
print ('Random weights at the start of training')
print (neural_network.weight_matrix)
train_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
train_outputs = array([[0, 1, 1, 0]]).T
neural_network.train(train_inputs, train_outputs, 10000)
print ('New weights after training')
print (neural_network.weight_matrix)
# Test the neural network with a new situation.
print ("Testing network on new examples ->")
print (neural_network.forward_propagation(array([1, 0, 0])))
خروجی مثال:
Random weights at the start of training [[-0.16595599] [ 0.44064899] [-0.99977125]] New weights after training [[5.39428067] [0.19482422] [0.34317086]] Testing network on new examples -> [0.99995873]